आर्टिफिशियल इंटेलिजेंस डिजिटल युग में एक नई कहानी लिख रहा हैं। इस टेक्नोलॉजी को बिज़नेस में काफी मात्रा में इस्तमाल किया जाता हैं। इसलिए आप देख सकते हैं कि ChatGPT, Claude.ai, OpenClaw, या फिर बाकी AI tools आज की तारीख में ज़रूरी हो गया है सीखना। Cybersecurity, content creation, और predictive analysis जैसे काम AI की वजह से ऑटोमेटेड हो जाता हैं।
इतने फायदे होने के बाद भी कंपनिया खुद का कोई AI मॉडल नहीं लॉन्च करती। और वजह साफ़ है कि AI model बनाने के लिए सिर्फ कोडिंग नहीं बल्कि एक सिस्टम की ज़रूरत होती हैं जो प्रॉब्लम को पहचानना, data acquisition, अल्गोरिथ्म्स चुनना, ट्रेनिंग और इवैल्यूएशन के साथ साथ डिप्लॉयमेंट और ऑनगोइंग मेंटेनेंस करना होता हैं।
विषयसूची
इन्हे पढ़े: Generative AI क्या है? जानिए यह भविष्य को कैसे बदल रहा है
AI मॉडल क्या है?
एक AI मॉडल एक कंप्यूटर प्रोग्राम या एल्गोरिदम है जिसे बड़े डेटासेट पर प्रशिक्षित किया जाता है ताकि वह पैटर्न को पहचान सके, निर्णय ले सके या ऑटोनोमस रूप से कंटेंट जेनरेट कर सके। यह एक डिजिटल “ब्रेन” की तरह काम करता हैं जिससे कुछ मुख्य टास्क जैसे कि Forecasting, image recognition या language generation करता हैं।
AI मॉडल के प्रमुख पहलू:
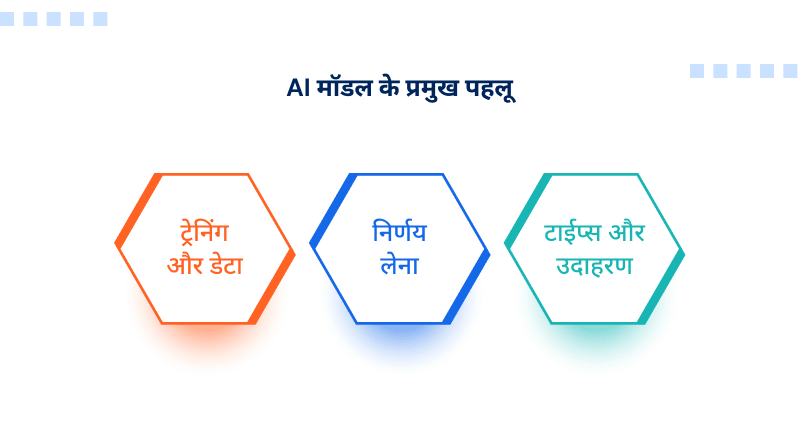
- ट्रेनिंग और डेटा: मॉडल बड़े डेटासेट पर एल्गोरिदम लागू करके बनाए जाते हैं, जिससे वे डेटा के भीतर रिलेशन को सीख पाते हैं।
- निर्णय लेना: एक बार ट्रेनिंग मिलने के बाद, वे प्रिडिक्शन्स, क्लासिफिकेशन या जनरेटिव आउटपुट (जैसे चैटबॉट प्रतिक्रियाएं) प्रदान करने के लिए नए, अनदेखे डेटा का एनालिसिस करते हैं।
- टाईप्स और उदाहरण: सामान्य प्रकारों में Generate AI (पाठ के लिए ChatGPT), कंप्यूटर विज़न (चेहरे की पहचान) और रेकमेंडेर सिस्टम (नेटफ्लिक्स रेकमेंडेशन) शामिल हैं।
इन्हे पढ़े: AI वेबसाइट बिल्डर से SEO फ्रेंडली वेबसाइट कैसे तैयार करें?
AI मॉडल्स कैसे काम करते हैं?
एक AI मॉडल को एक ऐसे प्रशिक्षु के रूप में सोचें जो कोई कौशल सीख रहा है। शुरुआत में, इसे (ह्यूमन्स, यानी ‘ट्रेनर्स’ द्वारा) कई उदाहरण (डेटा) दिखाए जाते हैं और सही उत्तर बताए जाते हैं। समय के साथ, यह अपने प्रयासों की तुलना उत्तरों से करता है, और बेहतर होने के लिए प्रत्येक दौर की प्रतिक्रिया के साथ अपने ‘ज्ञान’ को एडजस्ट करता है।
जिस प्रकार एक इंटर्न अभ्यास से बेहतर होता है, उसी प्रकार AI मॉडल ह्यूमन मॉनिटरिंग के जवाब में अपने पैटर्न और प्रिडिक्शन्स को पॉलिश करता है जब तक कि वह नए कार्यों को खुद से ही सटीक रूप से करने में सक्षम नहीं हो जाता।
इस ट्रेनिंग प्रोसेस में डेटा की क्वालिटी काफी ज़्यादा महत्वपूर्ण है।
ये मॉडल डेटा सेट से सीखते हैं, जो अक्सर बड़ी मात्रा में असंरचित डेटा सेट होते हैं, ताकि पैटर्न की पहचान कर सकें, स्पीच और इमेजेस को पहचान सकें और लैंग्वेज को समझ सकें।
इस ‘सीखने’ की तीन सामान्य कैटेगरीज़ हैं:
- Reinforcement learning
- Unsupervised learning
- Supervised learning
AI रिसर्चर्स AI मॉडल को ट्रेन करने और उनकी क्षमताओं को बेहतर बनाने के लिए इन तकनीकों के मिश्रण का इस्तमाल कर सकते हैं।
Deep neural network और एडवांस्ड आर्किटेक्चर, जैसे Generating pre-trained transformer (GPT) और डिफ्यूजन मॉडल, मुश्किल कार्यों को संभालने की उनकी क्षमता को और बढ़ाते हैं। ये मुश्किल लर्निंग एल्गोरिदम द्वारा ऑपरेट होते हैं।
इन्हे पढ़े: डेव टूल्स बनाम AI वेबसाइट बिल्डर्स, क्या AI वाकई समय बचाता है?
AI मॉडल बनाने की प्रोसेस
डेटा कलेक्शन
हाई-क्वालिटी डेटा काफी ज़्यादा ज़रूरी होता हैं AI मॉडल को बनाने में। टिम्स को डेटा प्रोजेक्ट गोल के हिसाब से बनाने की ज़रूरत हैं। इसमें आपका टेक्स्ट, इमेज, और सेंसर रीडिंग्स भी शामिल हैं।
सही डेटा की यह विशेषताएं होती हैं:
- प्रॉब्लम के हिसाब से उपयोग
- डाइवर्स और रिप्रेज़ेंटेटिव
- प्रॉपर लेबल
टिम्स को इस प्रकार का डेटा पब्लिक डेटासेट, APIs, वेब स्क्रैपिंग, या फिर खुद से बना सकते हैं। यह डेटा कितने मात्रा में चाहिए यह इस बात पर निर्भर करता हैं कि मॉडल कितना कॉम्प्लेक्स बनाना चाहते हैं।
डेटा क्लीनिंग और प्री-प्रोसेसिंग
रॉ डेटा का इस्तमाल शायद ही आप कर सकते हैं। उसके लिए क्लीनिंग और प्रेप-वर्क पहले करना ज़रूरी हैं। यह स्टेप आपके डेटा कंसिस्टेंट और यूजेबल बनाता हैं ट्रेनिंग के लिए:
कॉमन प्री-प्रोसेसिंग टास्क:
- डुप्लीकेट एंट्री को हटाना।
- एरर और टायपो को सुधारना।
- मिसिंग वैल्यूज़ को हैंडल करना।
- न्यूमरिकल फीचर्स स्केल करना।
- कैटगरिकल वेरिएबल्स इनकोड करना।
साफ़-सुथरा डेटा मॉडल की एक्यूरेसी और ट्रेनिंग की स्पीड को बेहतर बनाता है। इससे शुरुआती चरण में ही समस्याओं का पता लगाने में भी मदद मिलती है। टीमों को इस महत्वपूर्ण चरण के लिए पर्याप्त समय देना चाहिए।
सही टूल्स और फ्रेमवर्क चुनना
सही AI टूल्स चुनने से समय और मेहनत की बचत हो सकती है। चुनाव AI प्रोजेक्ट के प्रकार पर निर्भर करता है, चाहे आप पारंपरिक मशीन लर्निंग पर काम कर रहे हों या डीप लर्निंग पर।
डीप लर्निंग के लिए लोकप्रिय टूल्स में शामिल हैं:
- TensorFlow – डीप न्यूरल नेटवर्क बनाने और ट्रेन करने के लिए Google की ओपन-सोर्स लाइब्रेरी।
- PyTorch – Facebook द्वारा विकसित एक फ्लेक्सिबल डीप लर्निंग फ्रेमवर्क।
- Keras – TensorFlow के ऊपर चलने वाला एक उच्च-स्तरीय API, जो प्रॉम्प्ट प्रोटोटाइपिंग के लिए उपयोगी है।
पारंपरिक मशीन लर्निंग एल्गोरिदम (जैसे डिसीजन ट्री, सपोर्ट वेक्टर मशीन या लीनियर रिग्रेशन) के लिए, एक आम विकल्प है:
- Scikit-learn – ट्रेडिशनल ML मेथड्स के लिए विशेष रूप से डिज़ाइन की गई एक Python लाइब्रेरी।
इसके अलावा, AWS, Google Cloud और Microsoft Azure जैसे क्लाउड प्लेटफॉर्म पहले से निर्मित AI सेवाएं और बुनियादी ढांचा प्रदान करते हैं। ये विकास को गति देने में सहायक हो सकते हैं, विशेष रूप से उन टीमों के लिए जिनके पास व्यापक इंटरनल रिसोर्सेस नहीं हैं।
सही प्रोग्रामिंग लैंग्वेज चुनना
AI मॉडल बनाने के लिए Python प्रोग्रामिंग सबसे पहली चॉइस हैं। काफी ज़्यादा AI/ML लाइब्रेरिस जैसे कि TensorFlow, PyTorch, Keras, और Scikit-learn, Python प्रोगरामिंग लैंग्वेज पर बनाया गया हैं।
अगर आप Python लैंग्वेज को छोड़ कर दूसरे लैंग्वेज का इस्तमाल करना चाहते हैं तो यह रहे विकल्प:
- R – डेटा साइंस और स्टैटिस्टिकल एनालिसिस के लिए सबसे सही है, लेकिन आमतौर पर AI सिस्टम बनाने के लिए इसका उपयोग नहीं किया जाता है।
- Java – बड़े उद्यमों में इसका अक्सर उपयोग किया जाता है, विशेष रूप से AI मॉडल को लार्ज-स्केल ऍप्लिकेशन्स को इंटीग्रेट करने के लिए।
- C++ – आमतौर पर AI मॉडल लिखने के लिए इसका उपयोग नहीं किया जाता है, लेकिन यह इंटर्नल प्रोसेस में महत्वपूर्ण भूमिका निभाता है। कई AI लाइब्रेरी के मुख्य घटक प्रदर्शन के लिए C++ में लिखे गए हैं। यह रोबोटिक्स, एम्बेडेड सिस्टम और एज डिप्लॉयमेंट जैसे परिदृश्यों में भी उपयोगी है।
मॉडल सिलेक्शन और आर्किटेक्चर
AI मॉडल बनाने में सबसे क्रिटिकल डिसीजन यह होता है कि आप किस टाइप का मॉडल यूज़ करेंगे। हर प्रॉब्लम के लिए अलग आर्किटेक्चर होता है, इमेज recognition के लिए CNN (Convolutional Neural Network), Natural Language Processing के लिए Transformer, और टाइम-सीरीज़ या सीक्वेंस डेटा के लिए RNN या LSTM सबसे बेहतर माने जाते हैं।
गलत आर्किटेक्चर चुनने से अच्छे से अच्छा डेटा भी काम का नहीं रहता। इसलिए टीम्स को पहले यह समझना ज़रूरी है कि उनकी प्रॉब्लम classification है, regression है, या generation, उसके बाद ही मॉडल सिलेक्शन करें। प्री-ट्रेंड मॉडल्स जैसे BERT या ResNet को fine-tune करना भी एक स्मार्ट और टाइम-सेविंग ऑप्शन हो सकता है।
मॉडल ट्रेनिंग
ट्रेनिंग वो प्रोसेस है जहाँ मॉडल डेटा से पैटर्न्स सीखता है। इसमें लॉस फंक्शन डिफाइन किया जाता है जो बताता है कि मॉडल कितना गलत है, और ऑप्टिमाइज़र (जैसे Adam या SGD) उस गलती को कम करने की कोशिश करता है। लर्निंग रेट, बैच साइज़, और epochs जैसे हाइपरपैरामीटर्स ट्रेनिंग की क्वालिटी को सीधे इफेक्ट करते हैं।
ट्रेनिंग प्रोसेस काफी compute-intensive होती है और इसके लिए GPU या TPU की ज़रूरत पड़ती है। बड़े मॉडल्स को ट्रेन करने में घंटों से लेकर हफ्तों तक का समय लग सकता है। इसलिए टीम्स को ट्रेनिंग के दौरान loss curves मॉनिटर करनी चाहिए ताकि overfitting या underfitting जैसी प्रॉब्लम्स को जल्दी पकड़ा जा सके।
मॉडल इवैल्यूएशन
ट्रेनिंग के बाद मॉडल को उस डेटा पर टेस्ट किया जाता है जो उसने पहले कभी नहीं देखा — इसे test set कहते हैं। इसके लिए अलग-अलग metrics यूज़ होती हैं जैसे Accuracy, Precision, Recall, F1-Score classification के लिए, और RMSE या MAE regression टास्क के लिए।
सिर्फ accuracy देखना काफी नहीं होता, खासकर जब डेटा imbalanced हो। उदाहरण के लिए, अगर ९५% डेटा एक ही क्लास का है, तो मॉडल हमेशा वही क्लास प्रेडिक्ट करके भी ९५% accuracy दिखा सकता है। इसलिए confusion matrix और ROC curve जैसे टूल्स से डीप एनालिसिस करना ज़रूरी है।
हाइपरपैरामीटर ट्यूनिंग
हाइपरपैरामीटर्स वो settings होती हैं जो ट्रेनिंग से पहले manually सेट की जाती हैं, जैसे लर्निंग रेट, बैच साइज़, न्यूरल नेटवर्क की लेयर्स की संख्या, और dropout rate। इन्हें सही तरीके से सेट करना मॉडल की परफॉर्मेंस को काफी हद तक बेहतर बना सकता है।
इसके लिए Grid Search, Random Search, या Bayesian Optimization जैसी techniques यूज़ होती हैं। Optuna और Ray Tune जैसे टूल्स इस प्रोसेस को ऑटोमेट करने में मदद करते हैं। यह स्टेप time-consuming ज़रूर है, लेकिन एक बेहतरीन मॉडल और एक average मॉडल के बीच का फर्क यहीं से आता है।
मॉडल डिप्लॉयमेंट
एक बार मॉडल तैयार और इवैल्यूएट हो जाए, तो उसे रियल-वर्ल्ड यूज़ के लिए डिप्लॉय करना होता है। इसके लिए Flask या FastAPI से REST API बनाई जाती है, जिससे दूसरे ऍप्लिकेशन्स मॉडल को आसानी से कॉल कर सकें। क्लाउड प्लेटफॉर्म्स जैसे AWS SageMaker, Google Vertex AI, और Azure ML डिप्लॉयमेंट को स्केलेबल और मैनेजेबल बनाते हैं।
एज डिप्लॉयमेंट के लिए, जहाँ इंटरनेट कनेक्शन लिमिटेड हो, TensorFlow Lite या ONNX जैसे फ्रेमवर्क्स का इस्तमाल होता है जो मॉडल को lightweight बनाते हैं। डिप्लॉयमेंट स्ट्रैटेजी हमेशा यूज़ केस पर निर्भर करती है, चाहे वो मोबाइल ऍप हो, वेब सर्विस हो, या कोई इंडस्ट्रियल डिवाइस।
मॉनिटरिंग और मेंटेनेंस
डिप्लॉयमेंट के बाद मॉडल की ज़िम्मेदारी खत्म नहीं होती। रियल-वर्ल्ड में डेटा के पैटर्न्स समय के साथ बदलते रहते हैं, जिसे Model Drift कहते हैं। इससे मॉडल की एक्यूरेसी धीरे-धीरे कम होने लगती है, इसलिए परफॉर्मेंस को लगातार मॉनिटर करना ज़रूरी है।Prometheus, Grafana, या क्लाउड-बेस्ड मॉनिटरिंग टूल्स से मॉडल की predictions, latency, और एरर रेट्स ट्रैक की जाती हैं। जब भी मॉडल की परफॉर्मेंस एक threshold से नीचे जाए, तो नए डेटा के साथ re-training करनी पड़ती है। यह एक लगातार चलने वाला प्रोसेस है जो मॉडल को लंबे समय तक रिलेवेंट और एक्यूरेट बनाए रखती है।
निष्कर्ष
AI मॉडल बनाना आज पहले से कहीं ज्यादा आसान हो गया है, लेकिन सही दिशा और समझ होना बेहद जरूरी है। सही डेटा, सही एल्गोरिदम और लगातार टेस्टिंग के साथ आप एक प्रभावी AI मॉडल तैयार कर सकते हैं। चाहे आप शुरुआत कर रहे हों या अपने स्किल्स को आगे बढ़ाना चाहते हों, छोटे प्रोजेक्ट्स से शुरू करें, नए टूल्स सीखें और लगातार प्रैक्टिस करते रहें, क्योंकि AI की दुनिया में सीखना कभी रुकता नहीं है।
FAQs
१. AI model बनाने के लिए कौनसी programming language सीखनी चाहिए?
AI model बनाने के लिए सबसे ज़्यादा इस्तेमाल होने वाली programming language Python है। इसका syntax आसान है और इसमें AI/ML के लिए powerful libraries जैसे TensorFlow, PyTorch और Scikit-learn उपलब्ध हैं। अगर आप शुरुआत कर रहे हैं, तो Python सीखना सबसे बेहतर रहेगा। इसके अलावा R, Java और C++ भी कुछ specific use cases में काम आते हैं, लेकिन beginners के लिए Python ही best choice है।
२. AI model बनाने के लिए mathematics कितनी ज़रूरी है?
AI और Machine Learning में mathematics काफी महत्वपूर्ण भूमिका निभाती है, लेकिन शुरुआत में आपको बहुत advanced maths जानना जरूरी नहीं है। आपको बेसिक कंसेप्ट्स जैसे Linear Algebra, Statistics और Probability की समझ होनी चाहिए।
३. AI model को इंटरनेट पर कैसे deploy करें?
AI model को deploy करने के लिए आपको पहले उसे API या web app के रूप में कन्वर्ट करना होता है। इसके लिए आप frameworks जैसे Flask या FastAPI का इस्तेमाल कर सकते हैं। इसके बाद आप अपने model को cloud platforms जैसे Amazon Web Services, Google Cloud Platform या Microsoft Azure पर host कर सकते हैं।